En 2008 compartimos neste blogue unha
traducción libre do poster sobre reconto de materiais, cortantes e instrumental da National Association of Theatre Nurses (NATN) do Reino Unido do que por desgraza xa non hai acceso ó orixinal e neste intre que vou deixar de traballar no bloque cirúrxico coido que é interesante facer un repaso do tema.
O certo é que os chamados obxectos retidos involuntariamente (ORI) tras unha técnica invasiva son sucesos pouco frecuentes (1:55000 ciruxías (1)) mais con consecuencias moi graves. Un tipo de evento chamado "Evento centinela" tamén coñecidos como "Never events"e como ben nos indica a Análise Modal de Fallos i Efectos (AMFE) a capacidade de detección deste evento acabará por determinar o seu nivel de risco.
Esa capacidade de detección non pode depender da atención dos profesionais senon que debe basearse en metodoloxías ben artelladas e cun adestramento axeitado de tódolos participantes a seren posible en situacions semellantes á realidade.
AS CONSECUENCIAS
A literatura(2,3) reflicte unha longa lista de complicacions primarias debido a un ORI asociado a procesos cirúrxicos: Adherencias, Encapsulacions, Infección, Absceso, Obstrucción intestinal, Fístulas, Perforacion instetinal, Dor, Complicacions vasculares (trombosis, embolización, arritmia, taponamento, perforación)... moitas veces os ORI conlevan prolongación da estancia, reintervención, perda de órganos ou tecido e tamén morte.
A DIMENSIÓN DO PROBLEMA
A The Joint Commission (TJC) para a acreditación de organizacions sanitarias nos EEUU obriga non só a ter un sistema de notificación dos eventos centinela senon á realización dunha Análise Causa-Raiz (ACR) dos mesmos que quedan rexistrados na Oficce of Quality an Patient Safety. O sistema recolleu entre outubro de 2012 e septembro de 2017 319 notificacions que implicaban que unha "surgical sponge" quedara no interior dunha cavidade de xeito non intencionado tras un procedemento invasivo(4).
Dos ACR se obteñen datos inquedantes; só nun 77,4% dos casos se realizara un reconto e deses casos un 80,6% foi dado como "Correcto". Eses datos indican alguns fallos non só na metodoloxía do reconto senon na súa aplicación.
Ter en conta que as "surgical sponges" (item textil: gasa, compresa, talla ou pano etc) son só unha pequena parte dos múltiples obxectos que poden quedar esquecidos durante un procedemento invasivo; instrumentos, agullas, drenaxes, guías, marcadores, mostras de tecido, implantes, fragmentos de embalaxe de productos... poden significar un serio problema para o paciente.
MIRANDO MELLORAR.
O certo é que no noso medio por seren un suceso pouco frecuente e pola tendencia a tratar de ocultalos a mellor defensa que se pode facer non é agardar a que xurdan notificacions xa que sería algo moi moi improbable e co nivel actual de cultura de seguridade non se podería levar a cabo un ACR como é debido así que o seu sería que tratar de artellar un marco axeitado dende o punto de vista do apoio formal (documentado) a uns criterios e unha metodoloxía de traballo e de rexistro que, baseados na mellor evidencia dispoñible, den resposta ós diagnósticos de enfermería implicados. (De xeito ilustrativo e non limitativo na NANDA: 00035 "Risco de lesión", 00266 "Risco de infección de ferida cirúrxica" e 00246 "Risco de retraso na recuperación cirúrxica").
E Cal é a mellor evidencia dispoñible? pois ó meu modesto xuizo a que proporciona o JBI(6) é concisa e completa; en todo caso coa evidencia un grupo multidisciplinar da axencia de calidade ou das sociedades científicas implicadas pode construir unha guia de recomendacions para a contaxe cirúrxica que sirva de referencia ás equipas á hora de redactar os seus protocolos de reconto.
Por desgraza, tal e como mostra o propio ministerio de sanidade(5), para buscar un "patrón de ouro" que tomar como punto de referencia temos que irnos ó extranxeiro co problema que representa o diferente do sistema de acreditación profesional e do sistema xudicial.
A nivel internacional as principales referencias de guías de recomendacions para a realización do reconto cirúrxico as proporcionan a asociación americana AORN(7), a asociación europea EORNA(8), a asociación autraliana ACORN(9) e a asociación canadiana ORNAC(10).
PREVIR MELLOR QUE TAPAR.
Calquera que teña traballado no eido da calidade sabe que non basta con coñecer a evidencia, ter unha guía de recomendacions ou ter un protocolo; trátase de conquerir unha aplicación desas recomendacions. O concepto de auditoría clínica(11) vai mais aló dunha medida de cumprimento duns criterios e se enfoca nun proceso de mellora centrado nun campo clinico do que se toma unha imaxe da práctica tal e como se realiza, se avalia esa práctica para identificar as melloras requeribles e as diferenzas coa mellor práctica recomendada, se realizan actividades para implementa-los trocos requeridos e volta a avaliar nun verdadeiro ciclo de mellora continua.
Qué pasaría no voso medio si se fai unha auditoría do reconto cirúrxico? por exemplo seguindo estes criterios:
1) Seguese estritamente un plantexamento coherente e normalizado do reconto cirúrxico.
2) A equipa perioperatoria participa nunha formación para a prevención de obxetos cirúrxicos retidos baseada no traballo en equipa.
3) Mantense un entorno óptimo no quirófano evitando as interrupcions nas tarefas críticas como o reconto.
4) Se contan todolos materiais textis, obxectos punzantes e outros materiais abertos no campo cirúrxico.
5) Deben contarse os instrumentos cando exista alto risco de se producir un ORI; por exemplo cunha cavidade corporal aberta.
6) Existe un proceso normalizado para a resolución das discrepancias no reconto.
7) No caso de existires discrepancias toda a equipa cirúrxica leva a cabo as accions precisas para localiza-lo ítem extraviado.
8) A documentación inclue o resultado do reconto cirúrxico, a notificación os integrantes da equipa cirúrxica, os instrumentos ou ítems deixados intencionadamente como paking e as accions levadas a cabo no caso de que houbera discrepancias no reconto.
Como vedes hai elementos da auditoría que apuntan a ós tres tipos de compoñentes da calidade asistencial; de estrutura, de proceso e de resultado ainda que este último sexa de deixo indirecto (as discrepancias nos recontos) porque como sabemos no caso dos Eventos Adversos o que se trata e de aprendermos non de "contalos".
É certo que nestes criterios pode que botedes en falta algún; eu por exemplo boto en falta a esixencia dun criterio de estrutura básico: "Existe un dispositivo para rexistra-lo reconto á vista de tódolos integrantes da equipa cirúrxica".

RESULTADOS
Aplicados os criterios anteriores cunha mostra de 43 intervencions temos que os criterios:
1) Non se cumpre aínda. Hai un protocolo "en proceso" na comisión correspondente do centro.
2) Non se cumpre. Non se fai formación de prevención de ORI nen está prevista.
3) Cumprimento parcial. Ó non ter un protocolo as interrupcions no proceso de reconto dependen das circuntancias concretas.
4) Cumprimento parcial. Nun 74,42% das intervencions se contaron os materiais textis ó abrise no campo, nun 6,98% das intervencions se contaron os obxectos punzantes, en ningunha intervención se contaron outro tipo de items abertos no campo cirúrxico.
5) Cumprimento parcial. Nun 18,6% das intervencions se contaron os instrumentos ó inicio e ó final da intervención.
6) Non se cumpre. Ó non haber un protocolo non existe un procedemento normalizado no caso de discrepancias.
7) Cumprimento parcial. Na única discrepancia observada o incidente foi resolto polas enfermeiras após dunha percura ordeada dentro e fora do campo cirúrxico.
8) Cumprimento parcial. O rexistro en papel só inclue si o reconto de ítems textis ou o seu uso como packing, o emprego de técnicas de imaxe no caso de discrepancias se pode rexistrar. No 44,19% das ciruxías o reconto foi documentado. Só nun caso se deixou un ítem intencionadamente (hemostático).
O rexistro no aplicativo GACELA só permite poñer si o reconto de gasas, compresas e instrumental é correcto. Como xa expresei
na entrada anterior "son un paripé".
Temos pois, un punto de partida no que se pode dicir aquelo de "só queda mellorar"...
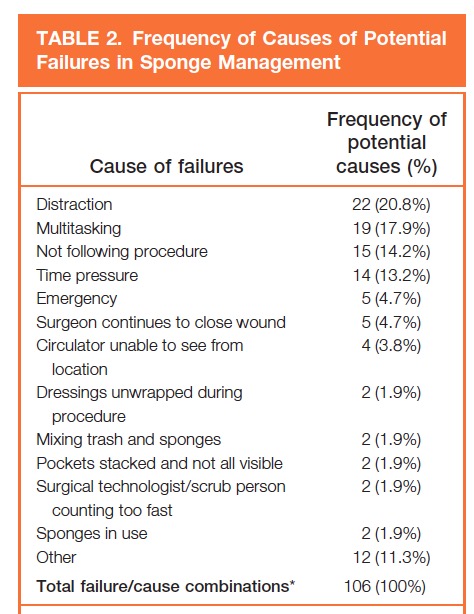
Como colofón quero compartir unha referencia moi interesante; "Deseño dun proceso seguro para evita-los ORI: Unha análise modal de fallos e efectos (AMFE)(12) no que, salvando as diferencias da estructura profesional e funcionamietno dos quirófanos nos EEUU, se desprega unha boa análise dos riscos de ORI e se mostran datos como os seguintes:
Que son moi útiles para sabermos porqué ainda realizando un reconto a conciencia este pode resultar falso.
BIBLIOGRAFÍA
1) Cima RR, Kollengode A, Garnatz J, Storsveen A, Weisbrod C, Deschamps C. Incidence and characteristics of potential and actual retained foreign object events in surgical patients. J Am Coll Surg. 2008;207:80.
2)Gawande AA, Studdert DM, Orav EJ, Brennan TA, Zinner MJ. Risk factors for retained instruments and sponges after surgery. N Engl J Med. 2003;348:229.
3) Lincourt AE, Harrell A, Cristiano J, Sechrist C, Kercher K, Heniford BT. Retained foreign bodies after surgery. J Surg Res. 2007;138:170.
4) Steelman VM, Shaw C, Shine L, Hardy-Fairbanks AJ. Retained surgical sponges: a descriptive study of 319 occurrences and contributing factors from 2012 to 2017. Patient Saf Surg [Internet]. diciembre de 2018 [citado 21 de diciembre de 2022];12(1):20. Disponible en: https://pssjournal.biomedcentral.com/articles/10.1186/s13037-018-0166-0
5) Ministerio de sanidad. Bloque Quirurgico Estándares y recomendaciones [Internet]. Madrid: MINISTERIO DE SANIDAD Y POLÍTICA SOCIAL; 2008 p. 300. (Estandares y recomendaciones). [citado 21 de diciembre de 2022] Disponible en: https://www.mscbs.gob.es/organizacion/sns/planCalidadSNS/docs/BQ.pdf 6) Whitehorn A. Evidence Summary. Operating Room: Surgical Counts. The Joanna Briggs Institute EBP. Database, JBI@Ovid. 2019; JBI5504
7)Recommendations-on-Prevention-of-retained-surgical-items-2019.pdf Cochran K. Guidelines in Practice: Prevention of Unintentionally Retained Surgical Items. AORN Journal [Internet]. noviembre de 2022 [citado 21 de diciembre de 2022];116(5):427-40. Disponible en: https://onlinelibrary.wiley.com/doi/10.1002/aorn.13804
8) Heen C, Sandelin A, Afraie D, Budiselic I, Elin M, Lepore M, et al. EORNA Recommendations on Prevention of retained surgical items [Internet]. EORNA; 2019.[citado 21 de diciembre de 2022] Disponible en:https://eorna.eu/wp-content/uploads/2019/05/
9) Australian College of perioperative nurses. ACORN Standards for Perioperative Nursing including Nursing roles, Guidelines and Position Statements [Internet]. 2013 [citado 21 de diciembre de 2022]. Disponible en: https://www.acorn.org.au/standards
10) Operating Room Nurses Association of Canada (ORNAC). Standards, Guidelines and Position Statements for Perioperative Registered Nursing Practice (15th Ed) [Internet] (2021) [citado 21 de diciembre de 2022]. Disponible en: https://www.csagroup.org/store/product/ORNAC-2021/
11)Pearson A, Field J, Jordan Z. Evidence Utilisation: Clinical Audit In:Evidence-Based Clinical Practice in Nursing and Health Care [Internet]. Oxford, UK: Blackwell Publishing Ltd.; 2006 [citado 21 de diciembre de 2022]. Disponible en: http://doi.wiley.com/10.1002/9781444316544








.jpg)